

 Пять однобайтных кодировок кириллицы
Пять однобайтных кодировок кириллицыТема 2. Представление информации (2 часа)
Дидактические единицы: Язык. Классификация языков. Функции естественных языков. Недостатки естественных языков. Объектные языки и метаязыки. Кодирование информации. Виды знаков. Буквы, алфавиты. Кодирование и декодирование. Представление в компьютере текстовой информации.
2. Кодирование информации. Виды знаков. Алфавиты, буквы.
3. Представление в компьютере текстовой информации.
4. Внутреннее представление символа в компьютере. Дополнительные сведения
1. Язык как способ представления информации. Классификация языков.
Существует множество определений языка. Язык определяется как
- "важнейшее средство человеческого общения"
- "вся система знаков"
- "только человеческая речь"
Под "языком" будем при дальнейшем изложении понимать материальную (звуковую по преимуществу) оболочку мысли.
Слово, являющееся единицей естественного языка, выступает в виде движущихся материальных слоёв воздуха, в виде звуков. Слово - материальное образование, языковой знак.
С точки зрения происхождения языки делятся на естественные (далее - ЕЯ) и искусственные (далее - ИЯ). У ЕЯ нет автора, автор - народ в целом. ИЯ всегда созданы кем-то, автор ИЯ чаще всего известен.
|
| ||
|
|
| |
|
Естественные языки (ЕЯ) суть особые знаковые системы, с них началось формирование человеческого сознания. Все другие знаковые системы являются производными от ЕЯ. ЕЯ являются универсальными знаковыми системами. |
представляют собой фрагмент естественного языка (тексты в учебниках литературы, русского языка, географии, истории) с уточнённым значением употребляемых слов. |
построены по определённым правилам, используют формулы и специальные символы (язык физики, математики, химии etс.) |
|
| ||
|
|
|
|
|
Communis (лат.) общий. Это функция общения с помощью языка, совместного узнавания, знания (СО-знания) |
До 3-4 лет ребёнок овладевает устной речью, которая открывает ему доступ к богатствам, накопленным национальной культурой. |
Называется ещё модальной. Это самая древняя функция языка. С её помощью говорящий выражает своё отношение к внеязыковой действительности. |
|
| |||
|
|
|
|
|
|
В ЕЯ многозначность слов обычно не доставляет неудобств, так как значение употребляемого слова определяется участниками общения контекстуально. |
Модальная функция языка, обычно характерная для устной повседневной речи, вносит субъективный элемент в процесс обмена информацией, чаще всего препятствует нахождению истины. В СИЯ, а особенно в ФИЯ, элементы субъективного отношения к внеязыковой действительности практически отсутствуют. В научных дискуссиях или в официальных выступлениях должностных лиц отрицательное отношение к противоположной точке зрения выражается лишь с помощью эвфемизмов. |
Лектор, выступающий перед неподготовленной аудиторией, вынужден тратить время на определение основных понятий, используемых им для раскрытия темы выступления. В ФИЯ термины чаще уже определены, поэтому тексты научной тематики короче устных пояснений лектора. |
Язык используется чаще всего как средство общения. Общение обычно предназначено для СО-знания общающихся, для построения программ поведения людей, продуктивных или контрпродуктивных. Но бывает общение и без обмена смыслами (разговор людей, вкладывающих разные смыслы в используемые слова (логомахии), ритуалы, прикосновения, поглаживания и т.п.). Такое общение выражает чувство общности, сопричастности к ней, симпатии или антипатии, участия (соучастия). |
|
| |||
|
|
| ||
|
μετα (греч.)- вне, за пределами - язык, известный носителю, чаще национальный ЕЯ, на основе которого изучается новый язык, ещё неизвестный. |
Язык, изучаемый на основе метаязыка. Для француза, приехавшего пожить в Китай, объектным языком будет китайский, метаязыком - французский. | ||
2. Кодирование информации. Виды знаков. Алфавиты, буквы.
|
| |||
|
|
|
|
|
|
Наглядные или звуковые изображения обозначаемых предметов (фотография человека, скульптура, карта местности, чертёж); сходство с объектом у этого вида знаков является обязательным. |
Носят конвенциальный характер (соглашения между людьми); возникли спонтанно или намеренно, но обязательно согласованы и общеприняты (дорожные, денежные, знаки приветствия, форменная одежда, флажковая сигнализация, азбука Морзе и т.п. ). |
Все слова и выражения нашего языка суть знаки. Каждый народ пользуется своим национальным языком. Большинство языковых знаков непохожи на замещаемый знаком (словом) предмет. |
Знаки "в чистом виде": символики, коды искусственных языков (формулы в математике, структурные формулы в химии, язык формальной логики, физики, геральдики). |
Информация подразделяют на два вида: аналоговую (непрерывную, континуальную) и дискретную (прерывную, прерывистую). Примером аналоговой информации может служить запись звука на магнитофонную ленту или колебаний температуры на ленту или диск самописца. Примером дискретной записи служит этот самый текст, который Вы сейчас читаете. Вычислительные машины (компьютеры) тоже обрабатывают и аналоговую, и дискретную информацию. Компьютеры, обрабатывающие непрерывный сигнал, называются аналоговыми вычислительными машинами (АВМ). Персональные компьютеры (электронные, цифровые вычислительные машины, ЭВМ), с которыми мы уже привыкли работать, обрабатывают дискретную информацию. Дискретная информация записывается с помощью некоторого конечного набора знаков, которые будем называть буквами.
Буква (в её расширенном понимании) - любой из знаков, которые некоторым соглашением установлены для общения. Вообще буквой будем называть элемент некоторого конечного множества (набора) отличных друг от друга знаков.
Множество знаков, на котором определён их порядок, назовём АЛФАВИТОМ. Вот названия некоторых алфавитов: латиница, кириллица, армянский, грузинский, алфавит арабских цифр, латинских цифр, византийских цифр, блок-схем изображения алгоритмов). Отдельную группу составляют двузначные (двоичные) алфавиты: [0 1]; [× —]; [• —].

В канале связи сообщение, составленное из букв (символов) одного алфавита, может преобразовываться в сообщение из букв (символов) другого алфавита.
Правило, описывающее однозначное соответствие букв алфавита при таком преобразовании, называется кодом. Саму процедуру преобразования сообщения называют перекодировкой.
Сообщения должно быть преобразовано в момент его поступления от источника в канал связи (кодирование), и в момент приёма сообщения получателем (декодирование). Люди или технические устройства, обеспечивающие кодирование (шифрование) и декодирование (дешифровку), называются соответ-ственно кодировщиком и декодировщиком (шифратором и дешифратором).
Люди шифруют свои сообщения для того, чтобы не допустить к важным знаниям профанов, для защиты от сведений, составляющих важную государственную тайну и пр. Так возникают всяческие тайнописи, арго субкультур, профессиональные жаргоны, которые отражают какую-то сферу реальной действительности и обслуживают потребность данной социальной группы в быстрой и адекватной передаче актуальной информации. Например, каменщики различают в кирпиче "тычок", "бочок" и "ложок" (грани кирпичного параллелепипеда). Полинезийцы называют коралловые рифы в зависимости от того, выступают или не выступают они над поверхностью океана, позволяют или не позволяют провести каноэ в данном месте. Вперёдсмотрящий матрос, произнеся всего одно слово, даёт возможность рулевому быстро принять решение, как и куда вести судно. Чем короче сигнал опасности, тем больше шансов выжить у владельцев-пользователей кода.
Создавая объектные языки субкультур, люди используют словарный состав метаязыка (чаще всего национального, иногда национального и иностранного), часто употребляя слова родного языка в неожиданном или непривычном для окружающих значении.
3. Представление в компьютере текстовой информации.Когда возникла нужда давать техническим устройствам команды, люди вынуждены были преобразовать буквы национального алфавита в последовательности простых сигналов и стали использовать для этого двоичные алфавиты (см. выше). Так как техническое устройство в целом или отдельные его части можно либо включить, либо выключить, люди стали кодировать такие состояния двумя буквами. Телеграфисты применяли для передачи сообщений точку и тире, физики и электрики обозначали положительный и отрицательный заряды как + и -. Математики, исследуя недесятичные позиционные системы счисления, использовали для двоичного счёта 0 и 1. Для этого сначала приходилось составлять кодировочные таблицы.
Много ли символов можно зашифровать, используя две буквы? Можно попробовать составлять из двух букв слова разной длины и смотреть результат.
| Двоичное слово | Кодируемый символ |
 |
 |
 |
 |
Получается, что если в кодовом слове будет всего одна двоичная буква, то таким словом можно закодировать две буквы какого-нибудь алфавита (для примера взята латиница). Теперь попробуем записать все возможные двухбуквенные двоичные слова (см. таблицу ниже).
| Двоичное слово | Кодируемый символ |
|
|
|
|
|
 |
|
 |
С помощью двухбуквенных двоичных слов оказалось возможным закодировать четыре символа алфавита. Увеличим длину двоичного слова до трёх букв.
| Двоичное слово | Кодируемый символ |
|
|
|
|
|
|
|
|
|

|
|
 |
|
 |
|
 |
С помощью трёхбуквенных двоичных слов можно закодировать 8 символов некоторого алфавита. Это увлекательное исследование можно продолжать, но и сейчас уже можно сделать некоторые выводы.
21=2, 22=4, 23=8 и т.д. Когда кодовое слово n прирастает на одну букву (арифметическая прогрессия), число кодируемых символов M растёт в геометрической прогрессии (степени двойки). Это можно выразить формулой 2n=M, где n=1, 2, 3, 4 ...
В универсальном преобразователе информации (компьютере) должны находиться все символы, необходимые человеку в быту и профессиональной деятельности. Оказалось, чтобы отразить это необходимое многообразие на экране монитора и выводимых текстах документов, достаточно закодировать с помощью двоичных кодов 256 различных символов, использовав для этого 8 двоичных разрядов (28=256).
В микроЭВМ (персональных компьютерах) чаще всего используется кодовая таблица ASCII (American Standart Code for Information Interchange), созданная в 1963 году. К достоинствам такой кодировки букв латиницы и кириллицы относится их естественное упорядочение, что важно при решении задач обработки текстов.
Поскольку производить персональные компьютеры для продажи частным лицам первыми стали американцы, в основу кодовой таблицы символов для знакогенератора видеоконтроллера компьютера IMB PC положили действовавшую тогда кодовую таблицу американских телеграфистов. В ней для кодирования 128 символов использовалось 7 двоичных разрядов (бит). Символы с кодами с 0-го по 127-й стали общей частью ASCII-таблицы для всех персональных компьютеров, выпускаемых в дальнейшем. В ASCII символы с 0-го по 31-й связаны с управляющими клавишами клавиатуры, символы с 32-го по 127-й - c алфавитно-цифровыми.
 |
 |
Благодаря общей части ASCII-таблицы, фактически ставшей стандартом кодировки текстовых символов в ЭВМ, персональные компьютеры на всей планете могут "понимать" друг друга. У любого из них коды текстовых символов с 0-го по 127-й совпадают. При передаче сообщений с компьютера на компьютер из страны в страну один символ национальной части кодовой таблицы кодируется двумя символами общей части кодовой таблицы. Именно поэтому SMS, написанные кириллицей, которые посылает абонент мобильной телефонной сети, приблизительно в два раза короче SMS, написанных латиницей.
У романо-германских стран в их национальных алфавитах, принятых на основе латиницы, более 26-и символов. Когда персональные компьютеры IBM PC стали экспортировать за пределы США, программистам IBM пришлось увеличивать на один бит кодировочную таблицу, и в ней стало возможным закодировать 256 символов. Следовавшая за общей частью кодовой таблицы символов её расширенная часть, предложенная IBM, включила в себя буквы алфавитов европейских народов, специфические знаки препинания испанского, математические символы, дроби, степени, греческие буквы, символы "псевдографики", употреблявшиеся для рисования таблиц и т.п. Кодировка стала однобайтной (восьмибитной). Это значит, что двоичное слово, кодировавшее один символ, состояло из восьми букв двоичного алфавита.

Первой фирмой, выпустившей русифицированную операционную систему, была Apple. Русифицированные персональные компьютеры "Макинтош", появившиеся в конце 80-х, имели свою собственную, ни с чем не совместимую кодировку кириллицы для Mac OS (см. таблицу ниже). Её можно встретить в мировой паутине (WWW).

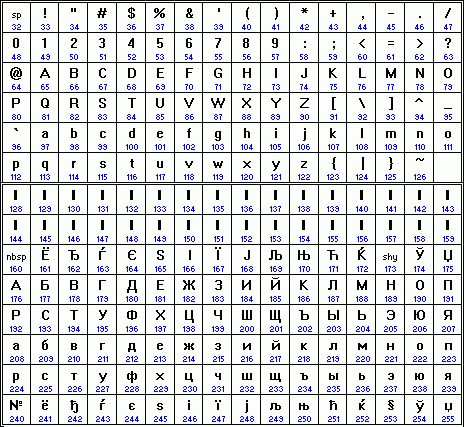
Хронологически одним из первых стандартов кодирования русских букв на компьютерах был КОИ8 ("Код обмена информацией, 8-битный"). Эта кодировка применялась ещё в советские времена на компьютерах серии ЕС ЭВМ, и когда в середине 80-х появились первые русифицированные версии операционной системы UNIX, они переняли эту кодировку у своих "старших братьев". Сеть Релком, с которой начинался российский Интернет в начале 90-х и которая поначалу состояла в основном из компьютеров с UNIX, также приняла кодировку КОИ8 в качестве стандартной. Сейчас КОИ8-Р является единственно допустимой кодировкой в русскоязычной электронной почте и телеконференциях. КОИ8-Р - одна из кодировок, которые обязательно должна поддерживать любая русская страница в WWW (см. таблицу ниже).

Кодировочные таблицы IBM-совместимых компьютеров, попавших в СССР, советские программисты заполняли символами кириллицы в разных местах расширенной части. Достаточно сказать, что существовали "основная кодировка ГОСТ" и "альтернативная кодировка ГОСТ". Властные органы рекомендовали пользоваться основной кодировкой, но подавляющее большинство пользователей очень скоро перешли на более практичную и удобную "модифицированную альтернативную кодировку ГОСТ". В ней некоторые математические символы и символы псевдографики совпадали с IBM-кодировкой, а русские буквы встали на те позиции, где у IBM-таблицы стоят греческие, французские, немецкие и т.п. Это давало возможность прямого использования англоязычных программ. Кодовая страница (code page), созданная IBM для России (её номер 866), позволяла работать на IBM-совместимом компьютере под управлением операционной системы MS-DOS. Эта кодировка русских символов CP866 для IBM-совместимых компьютеров, работавших под управлением ОС MS DOS, называется иногда OEM-кодировкой (см. таблицу ниже).

После написания графической оболочки Windows символы "псевдографики" стали излишними - в Windows-приложениях линии или диаграммы можно нарисовать непосредственно. К тому же в OEM-кодировке, предложенной IBM для MS DOS, не хватало многих символов европейских языков. Поэтому корпорация Microsoft разработала для Windows новую кодовую таблицу, называемую однобайтной ANSI-кодировкой. Алфавитно-цифровая часть кодовой страницы от Microsoft для России (code page 1251) представлена ниже.

Международная организация по стандартизации (International Standards Organization, ISO) утвердила в качестве стандарта для русского языка ещё одну кодировку под названием ISO 8859-5. Эта кодировка была принята лишь в очень ограниченном количестве программных и аппаратных продуктов (в основном тех, которые русифицировались на Западе людьми, незнакомыми с реальным положением дел в компьютерной кириллице). Поэтому ISO 8859-5 в компьютерном мире встречается крайне редко (см. таблицу ниже).
Выше описывались однобайтные кодировки. Считается, что на сегодняшний день существуют пять однобайтных кодировок русского кириллического восточнославянского алфавита (Mac, КОИ8-Р, OEM (cp866), ANSI (cp1251), ISO 8859-5).
В настоящее время всё большее распространение приобретает двубайтная кодировка Unicode, в ней коды символов могут принимать значения от 0 до 65535, что позволяет закодировать 65536 символов. Полная спецификация стандарта Unicode представляет собой довольно толстую книгу и включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов. Есть надежда, что для русского языка Unicode со временем сможет "вытеснить" все остальные кодировки. Чтобы составить представление о возможностях Unicode, достаточно в текстовом процессоре Word заняться вставкой символов шрифтами Winding, Webding или выбрать в списке шрифты с названиями, включающими в себя слово "Unicode".
4. Внутреннее представление символа в компьютере. Дополнительные сведения
Чтобы Вы могли представить себе, как коды букв существуют внутри компьютера, рассмотрите рисунок ниже. На нём отображён один из способов передачи данных внутри компьютера цепочкой импульсов. Так "представляется" компьютеру русская буква "Т" (код 21010 = 110100102) - приблизительно так же, как и всякая иная буква или цифра кодировочной таблицы.

Рассмотрите общую часть кодовой таблицы символов ASCII на рисунке ниже. Верхняя строка, выделенная тёмным цветом, показывает нам служебные (командные) символы, связанные с управляющими клавишами клавиатуры компьютера.

| Десятичный код |
Шестнадцате- ричный код |
Управляющая клавиша |
Действие клавиши |
Отображение |
| 000 | 00h | NUL | пустой символ | |
| 001 | 01h | SOH | начало заголовка |  |
| 002 | 02h | STX | начало текста |  |
| 003 | 03h | ETX | конец текста | ♥ |
| 004 | 04h | EOT | конец передачи | ♦ |
| 005 | 05h | ENQ | запрос | ♣ |
| 006 | 06h | ACK | подтверждение | ♠ |
| 007 | 07h | BEL | звонок |  |
| 008 | 08h | BS | возврат на одну позицию |  |
| 009 | 09h | HT | горизонтальная табуляция |  |
| 010 | 0Ah | LF | перевод строки |  |
| 011 | 0Bh | VT | вертикальная табуляция |  |
| 012 | 0Ch | FF | подача бланка (новый лист) |  |
| 013 | 0Dh | CR | возврат каретки |  |
| 014 | 0Eh | SO | переход на верхний регистр |  |
| 015 | 0Fh | SI | переход на нижний регистр |  |
| 016 | 10h | DLE | переключение кода |  |
| 017 | 11h | DC1 | управление 1-ым устройством |  |
| 018 | 12h | DC2 | управление 2-м устройством |  |
| 019 | 13h | DC3 | управление 3-м устройством | !! |
| 020 | 14h | DC4 | управление 4-м устройством | ¶ |
| 021 | 15h | NAK | переспрос | § |
| 022 | 16h | SYN | режим синхронного ожидания |  |
| 023 | 17h | ETB | конец передачи блока |  |
| 024 | 18h | CAN | отмена | ↑ |
| 025 | 19h | EM | конец носителя | ↓ |
| 026 | 1Ah | SUB | замена | → |
| 027 | 1Bh | ESC | переход | ← |
| 028 | 1Ch | FS | разделитель файла |  |
| 029 | 1Dh | GS | разделитель группы | ↔ |
| 030 | 1Eh | RS | разделитель записи |  |
| 031 | 1Fh | US | разделитель блока |  |
| 127 | 7Fh | DEL | стирание |  |
© Σταυρος Τεκτονος





 ©StavrosTektonos
©StavrosTektonos